(VOC.VN) - Khái niệm về cỗ máy tìm kiếm rất đơn giản. Vị trí cơ sở dữ liệu của các trang và trả về kết quả tìm kiếm có liên quan nhất. Công cụ tìm kiếm sơ khai chỉ hiểu các từ trên các trang web trong cơ sở dữ liệu của họ và các trang bao gồm các từ tìm kiếm trả về. Về cơ bản, Google đang sắp xếp lại các kết quả tìm kiếm dựa trên số kết quả tìm kiếm và chỉ hiển thị những kết quả phù hợp nhất cho người dùng. Ví dụ như "sự mới mẻ" của nội dung hoặc vị trí của nơi tìm kiếm đang diễn ra.
Panda chỉ là một cách để Google sắp xếp lại kết quả tìm kiếm dựa trên chất lượng nội dung của một trang web.
Trong bài viết này chúng ta hãy suy nghĩ chi tiết hơn về những gì có thể học được từ "bằng sáng chế Panda". Những dòng văn bản dài đó thường khiến người ta cảm thấy mơ hồ và đôi khi nó rất khó để hiểu theo đúng nghĩa. Vì vậy, đây là một vài khái niệm nhanh giúp bạn hiểu rõ các khái niệm này.
1. Panda làm thay đổi các thông tin thu thập về các liên kết và những câu hỏi liên quan đến một trang web.
2. Khi một người dùng tìm kiếm, mỗi kết quả được liệt kê (URL / Page) được đưa ra dựa trên sự liên quan để tìm kiếm và chất lượng trang.
3. Các tính toán của #1 và #2 sẽ xác định nếu danh sách kết quả (URL / Page) trên hoặc dưới một ngưỡng nào đó.
4. Kết quả được sắp xếp lại theo giá trị cuối cùng.
Cùng nhìn lại những xếp hạng Panda cũ và mới
Trở lại vào tháng 2 năm 2011, Google đưa ra một thay đổi lớn theo cách họ đặt kết quả tìm kiếm. Trong đó họ giải thích:
Bản cập nhật này được thiết kế để làm giảm thứ hạng của những trang web chất lượng thấp, sao chép nội dung từ các trang web khác.
Họ nói thêm rằng:
...Nó quan trọng đối với các trang web chất lượng cao để được khen thưởng và đó chính xác là những thay đổi.
Panda nhìn vào nội dung chất lượng vì nó có liên quan đến một trang web.
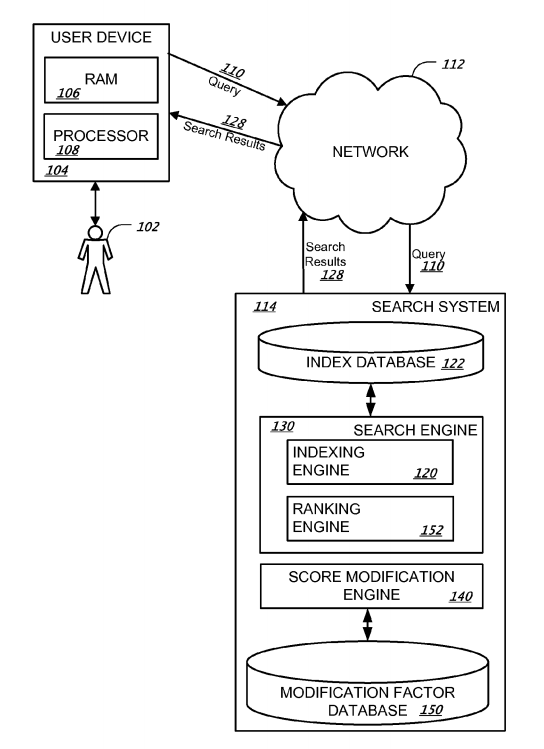
Tóm lại: Google chỉ định mỗi trang phù hợp cho kết quả tìm kiếm để tìm kiếm bất kỳ câu hỏi cụ thể nào dựa trên chất lượng của nhóm (ví dụ như một trang web) trang có liên quan với nhau. Đó là một bản tóm tắt được đóng gói và có vẻ như rất phức tạp để lập trình tự động.
Danny Sullivan - người sáng lập ra Search Engine Land nói đến điều này trong một bài viết được xuất bản sau 4 tháng khi Panda được tung ra: "Ngay bây giờ, đó là khả năng tính toán quá nhiều để chạy các phân tích cụ thể của các trang. Thay vào đó, Google chạy các bộ lọc định kỳ để tính toán các giá trị cần thiết".
Chúng tôi đã được biết đến những gì được mô tả ở dưới đây khi nó được làm mới, nó đánh dấu sự kiện của các trang web bị đánh trúng hoặc được công bố từ Panda.
Lưu ý: Theo Google, gần đây họ thường xuyên tích hợp vào tiến trình của họ, do đó nó không được coi là "làm mới".
Hơn 3 năm có tới 25 bản cập nhật Panda được đưa ra khi Bill Slawski phát hiện ra một bằng sáng chế được cấp với cái tên là Navneet Panda, các kỹ sư của Google - những tác giả của bản cập nhật Panda. Bill lưu ý rằng "...nó nhằm mục đích để cải thiện kết quả tìm kiếm hơn là xử phạt các trang web hoặc nỗ lực phát hiện ra những kết quả tìm kiếm được thao túng". Đây là một khác biệt quan trọng khi so sánh Panda với các bản cập nhật khác của Google.
Để giúp cung cấp một vài ngữ cảnh khi phân tích bằng sáng chế bên dưới, chúng tôi sẽ gọi nhóm mới dựa trên điểm chiết lượng mà Google tạo ra cho Panda. Bài viết ngợi ca cách Google xác định các trang có liên quan đến các truy vấn và PageRank.
Bằng sáng chế "Panda Rank"
Chúng ta có thể thu thập càng nhiều vấn đề phức tạp của một bằng sáng chế càng tốt, chúng ta có thể tóm tắt những vấn đề cơ bản nhất về Panda chỉ trong hai phần. Đối với mỗi URL hợp lệ cho một truy vấn tìm kiếm cụ thể:
- Điểm số ban đầu được tạo ra - cấp URL, liên quan đến truy vấn, và/hoặc điểm chất lượng.
- Nếu có thể, nhóm các yếu tố thay đổi đã được áp dụng.
Điểm đầu tiên
Bước đầu tiên trong việc tạo ra Panda Rank đã tạo ra một số điểm ban đầu cho mỗi danh sách URL trong bối cảnh của một truy vấn cụ thể. Các bằng sáng chế đi sâu vào chi tiết hơn, "... thước đo sự liên quan của các nguồn tài nguyên (danh sách URL) để truy vấn tìm kiếm, một thước đo chất lượng của nguồn tài nguyên (danh sách URL) hoặc cả hai".
Bước 1: Với thuật ngữ tìm kiếm, gán giá trị ban đầu cho tất cả các URL hợp lệ dựa trên:
- Liên quan đến truy vấn
- Thước đo chất lượng
Tóm tắt và dự đoán ban đầu
Điểm số ban đầu được tạo ra từ các yếu tố không phải là mới. Panda là đặc biệt vì nó là một phương pháp khả thi để tự động sắp xếp lại kết quả tìm kiếm dựa trên nhóm URL chất lượng.
Yếu tố thay đổi dựa vào nhóm
Khi số điểm ban đầu được tạo ra cho tất cả các URL đối với một truy vấn tìm kiếm nhất định, số điểm sau đó được sửa đổi dựa trên chất lượng của nhóm các URL đã được chỉ định.

Một trang web là một loại nhóm, Google đề cập đến cách giải quyết dựa vào nhóm nhiều lần trong các bằng sáng chế nhưng khả năng cung cấp của một nhóm có thể là:
...Một phần của các nguồn tài nguyên trên Internet. Một nhóm có thể xác định theo nhiều cách khác nhau.
Một nhóm địa chỉ dựa vào các nguồn tài nguyên là một nhóm các nguồn tài nguyên được xác định bởi các địa chỉ Internet chẳng hạn như Uniform Resource Locators (URLs), các nguồn tài nguyên trong nhóm. Các nguồn tài nguyên được nhóm lại sao cho một nguồn tài nguyên không thể được đưa vào nhiều hơn một nhóm tài nguyên. Chẳng hạn như một nhóm tài nguyên có thể bao gồm các tài nguyên này có thể được truy cập bằng cách sử dụng một tên miền cụ thể. Có nghĩa là, nhóm đó có thể bao gồm:
http://www.domain.com/resource1,
http://wwww.domain.com/resource2,
http://www.domain.com/resourceN
và như vậy nó sẽ không quan tâm cho đến khi nguồn tài nguyên đầu tiên có sẵn cho 130 động cơ tìm kiếm để lập chỉ mục. Ngoài ra, một nhóm các nguồn tài nguyên có thể bao gồm một tài nguyên có thể truy cập bằng cách sử dụng một tên máy chủ cụ thể, chẳng hạn như:
http://host.example.com/resource1,
http://host.example.com/resource2,
http://host.example.com/resourceN
Các nhóm địa chỉ khác là có thể xảy ra. Ví dụ, một nhóm đặc biệt có thể bao gồm một phần các nguồn tài nguyên có thể được truy cập bằng cách sử dụng tên máy chủ cụ thể hoặc một tên miền cụ thể.
Bước 2: Sau khi số điểm ban đầu được gán cho các URL đủ điều kiện cho một thuật ngữ tìm kiếm, điều chỉnh điểm số theo chất lượng của nhóm mà chúng được liên kết. Với mọi URL trong nhóm, điểm số chất lượng dựa vào việc xác định:
- Các truy vấn tham chiếu
- Các liên kết độc lập.
Đếm nhóm truy vấn tham chiếu
Một truy vấn tham chiếu là khi một người tìm kiếm sử dụng một truy vấn tìm kiếm để tìm một URL cụ thể.
Lưu ý: Chi tiết hơn được cung cấp về các truy vấn tham chiếu trong dòng chảy Panda và tổng kết suy đoán ở bên dưới.
Đếm nhóm liên kết độc lập
Liên kết độc lập đặc biệt "được kiểm tra rất kỹ lưỡng" các liên kết trỏ đến một URL.
Tóm tắt và dự đoán những thay đổi
Panda liên quan đến cấp URL ban đầu, điểm chất lượng và biến đổi chúng theo một nhóm yếu tố dựa vào các truy vấn tham chiếu và các liên kết độc lập.
Panda Flow
Những hình ảnh dưới đây mô tả bằng sáng chế của Panda
- Tạo ra các điểm ban đầu cho tất cả các danh sách URL đủ điều kiện cho một truy vấn tìm kiếm cụ thể.
- Xác định xem nếu truy vấn là điều hướng, nếu nó là truy vấn điều hướng thì khởi tạo điểm số ban đầu.
- Nếu số điểm khởi tạo của URL là dưới ngưỡng nhóm điểm chất lượng thì điều chỉnh điểm số ban đầu.
- Lặp lại
Lưu ý: trong các bằng sáng chế trên thực tế, chúng dường như đề cập đến một URL và coi chúng như là một "nguồn tài nguyên".
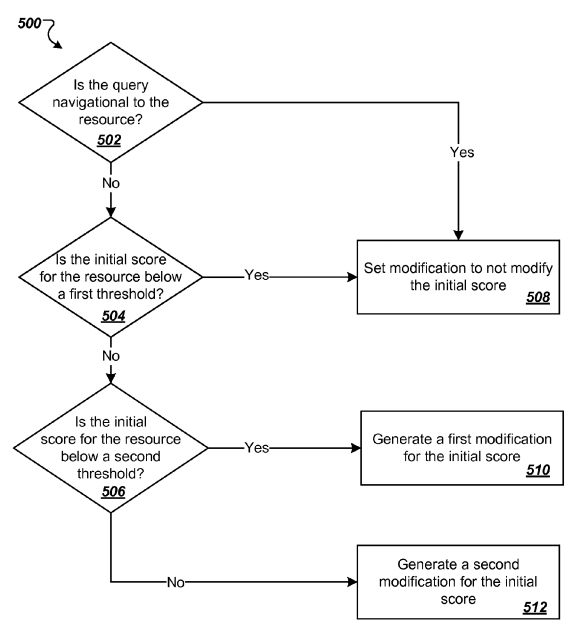
Tóm tắt và suy đoán Panda Flow
Một khía cạnh khó hiểu của Panda Flow là sự khác biệt giữa các truy vấn có định hướng và các truy vấn có thể tham chiếu được. Chúng tôi nghĩ rằng các truy vấn định hướng có thể có một cái gì đó cho biết tên thương hiệu trong truy vấn chính nó.
Chẳng hạn như tìm kiếm [nike shoes on zappos] có thể được coi là truy vấn điều hướng. Truy vấn tham chiếu có thể dựa vào thời gian. Nếu ai đó sử dụng một tìm kiếm và click vào một liên kết trong một khoảng thời gian nhất định thì nó có thể được gắn cờ và được coi là một "truy vấn tham chiếu".
Một ví dụ khác để về dòng chảy này để xem xét khả năng của nhiều ngưỡng. Điều đó có nghĩa là Google muốn có một yếu tố chất lượng dựa vào trang web hoặc một nhóm các URL và thấy rằng, với Panda có nhiều ngưỡng có thể cho các kết quả khác nhau. Các URL được liệt kê cho một truy vấn tìm kiếm cụ thể có thể là:
- Tác động tiêu cực bởi nhiều yếu tố điểm số theo nhóm
- Tác động tiêu cực bởi một yếu tố điểm số theo nhóm và tác động tích cực từ phía người khác.
- Tác động tích cực bởi nhiều yếu tố điểm số theo nhóm.
Bằng sáng chế "Các nguồn tài nguyên được nhóm lại để một nguồn tài nguyên không thể chứa trong nhiều nhóm tài nguyên".
Mặc dù điều này đã được tuyên bố, suy nghĩ rằng một URL có thể có yếu tố điều chỉnh được áp dụng dựa vào cả hai nhóm địa chỉ và không có địa chỉ.
Google có thể thiết lập địa chỉ dựa vào yếu tố sửa đổi để có nhiều hơn một tác động trên một URL. Kết quả là URL/các trang có vấn đề trùng lặp nội bộ cao hơn so với các URL/các trang với các vấn đề được sao chép lại từ bên ngoài.
Theo đó, nếu một trang web gặp vấn đề về chất lượng nhóm cả bên trong và bên ngoài, nó có thể chịu tác động tiêu cực đến hai lần.
Panda hiện tại và xem xét các yếu tố xếp hạng
Không cần suy nghĩ chi tiết nhưng có một điều chúng ta có thể đồng ý là trang web và nhóm điểm chất lượng là một yếu tố xếp hạng trong kết quả tìm kiếm của Google ngày nay. Có những điều chắc chắn đã thay đổi từ bằng sáng chế này nhưng nó cũng cung cấp sự hiểu biết quý báu về cách suy nghĩ và làm thế nào để tránh và khắc phục hình phạt từ Panda.
Như nó đã được mô tả trong bằng sáng chế, các URL được cấp một số điểm duy nhất được điều chỉnh theo bất kỳ truy vấn tìm kiếm. Hơn nữa, các yếu tố thay đổi là động phụ thuộc vào việc thay đổi. Điều đó có nghĩa là Panda sẽ có những tác động khác nhau dựa vào mỗi URL. Việc xác định số lượng là rất khó nhưng cũng có những yếu tố đã được thảo luận chi tiết ở trên để tiếp tục xem xét kết hợp với những thực hành tốt nhất:
Panda xếp hạng các yếu tố cấp URL
- Liên quan đến truy vấn
- Chất lượng
Panda xếp hạng nhóm các yếu tố
- Đếm các truy vấn tham chiếu
- Đếm các liên kết độc lập
Bằng sáng chế Panda khá là thú vị. Để hiểu rõ hơn về vấn đề này bạn nên kiểm tra và phân tích bằng sáng chế của Bill Slawksi, tại đây ông đã đề cập chi tiết hơn vào một trong số những yếu tố về Panda Rank.
Ghi nguồn www.voc.vn khi đăng tải lại bài viết này.
Bài viết có tham khảo và sử dụng nội dung từ Search Engine Watch.
Link: Tìm hiểu về các hoạt động kỹ thuật bên trong của Google Panda.